Major Cloud Outage Causes and Prevention
In our hyper-connected digital economy, the cloud is the invisible engine powering everything from streaming entertainment and social media to global finance and healthcare. We have come to rely on its omnipresence and resilience, often taking its seamless operation for granted. However, this reliance was starkly interrupted during a recent, widespread cloud outage that left millions of users stranded and countless businesses paralyzed. This event was not an isolated incident but a powerful reminder of the complex fragility within our digital infrastructure. This comprehensive analysis delves deep into the anatomy of a major cloud outage, exploring the root causes, the cascading domino effect, the profound business impact, and, most importantly, the essential strategies every organization must implement to build resilience and ensure continuity in an unpredictable digital world.
A. The Anatomy of a Crash: Deconstructing a Major Cloud Outage
A cloud outage is more than just a “service disruption.” It is a complex chain of failures within a highly interdependent system. Understanding its anatomy is the first step toward prevention.
A. The Illusion of Infallibility and the Shared Responsibility Model:
Many businesses operate under the misconception that migrating to the cloud transfers all risks to the cloud provider. This is a dangerous fallacy. Cloud providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) operate on a Shared Responsibility Model. They are responsible for the security of the cloud—the infrastructure, hardware, software, and networking. However, customers are responsible for security in the cloud—how they configure their services, manage access, architect their applications for failover, and back up their data. A misconfiguration on the customer’s end can be just as catastrophic as a failure in the provider’s data center.
B. The Domino Effect: How a Single Failure Cascades:
Modern cloud architecture is a web of microservices and dependencies. A failure in one seemingly minor component can trigger a cascade of failures across the entire ecosystem. For instance:
-
A failure in a core networking service can prevent authentication servers from communicating.
-
This, in turn, makes it impossible for users to log in, even if the application servers themselves are healthy.
-
Automated scaling systems, unable to authenticate, might fail to spin up new instances to handle load, exacerbating the problem.
This interconnectedness means that there is rarely a single point of failure; instead, there is a chain reaction that amplifies the initial issue.
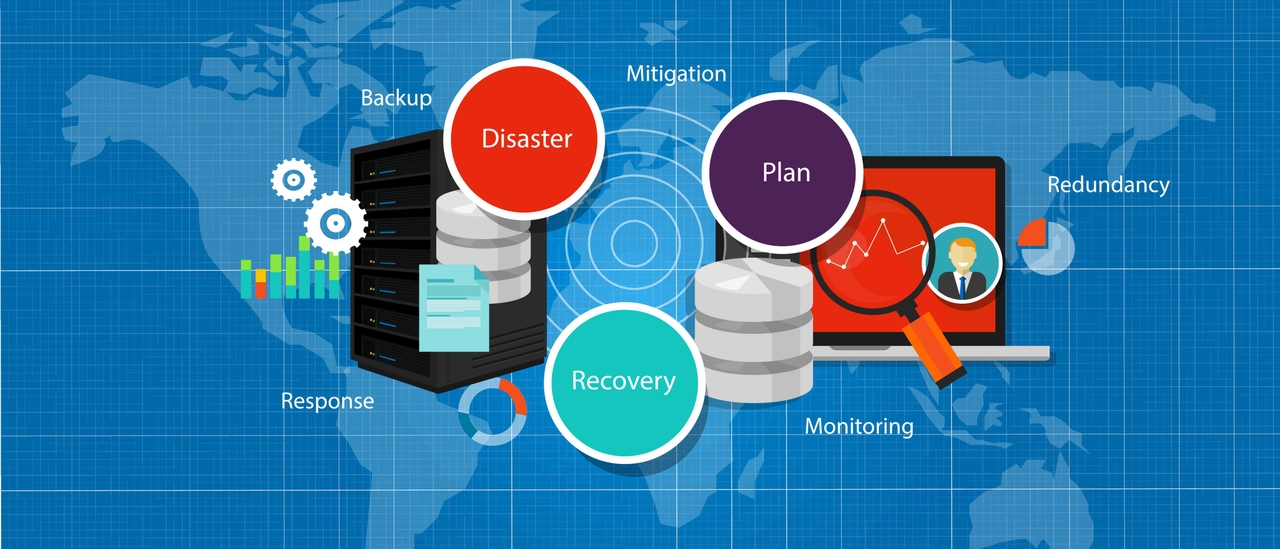
C. The Timeline of an Outage: From Detection to Resolution:
Understanding the lifecycle of an outage helps manage expectations and response.
A. Initial Trigger: An event occurs, such as a network device failure, a power loss, or a software bug deployment.
B. Service Degradation: Some users begin experiencing errors or latency. Monitoring systems may trigger initial alerts.
C. Full-Blown Outage: The failure cascades, rendering core services unavailable to the majority of users. The provider officially declares an outage.
D. Diagnosis and Mitigation: Engineering teams work to identify the root cause and implement a fix, which may involve rerouting traffic, rolling back software, or replacing hardware.
E. Service Restoration: Services are gradually restored, though some residual issues may persist as caches clear and systems stabilize.
F. Post-Mortem and Analysis: The provider publishes a detailed report explaining the cause, impact, and steps taken to prevent recurrence.
B. The Root Causes: Why Cloud Giants Stumble
The causes of major outages are as varied as they are complex. They often stem from a combination of technical failure, human error, and external threats.
A. Network Infrastructure Failures:
The network is the central nervous system of the cloud. When it fails, everything fails.
-
DNS (Domain Name System) Outages: If the DNS service that translates human-readable domain names (e.g., www.example.com) into machine-readable IP addresses fails, entire regions of the internet can become unreachable, even if the underlying servers are fine.
-
BGP (Border Gateway Protocol) Misconfigurations: BGP is the protocol that routes traffic between large networks on the internet. A single misconfiguration in a BGP announcement can accidentally reroute, or “hijack,” massive amounts of traffic, causing widespread blackouts.
-
Physical Fiber Cuts: Construction accidents, natural disasters, or sabotage can sever the physical undersea or terrestrial cables that form the backbone of global internet connectivity.
B. Software Bugs and Faulty Deployment Procedures:
The software that manages the cloud is immensely complex. A bug in a core service or a flawed deployment can have catastrophic consequences.
-
Failed Updates and Patches: A routine software update intended to fix a minor bug can inadvertently introduce a new, critical vulnerability or cause service instability.
-
“Thundering Herd” Problems: When a failed service restarts, all dependent systems may simultaneously try to reconnect, creating a massive, overwhelming surge of traffic that knocks the service back offline in a vicious cycle.
-
Insufficient Testing: Pushing code to production without adequate testing in a staging environment, especially for “canary deployments” (rolling out to a small subset of users first), can unleash bugs on a global scale.
C. Power Supply and Cooling Catastrophes:
Data centers are power-hungry facilities. Their uninterrupted operation depends on redundant power systems.
-
UPS (Uninterruptible Power Supply) Failure: If the primary power fails, the UPS is supposed to take over instantly until backup generators kick in. A failure in the UPS system itself can lead to an immediate shutdown.
-
Generator Failure: Backup generators can fail to start due to mechanical issues or fuel supply problems.
-
Cooling System Failure: Even if power is maintained, a failure in the precision cooling system can cause servers to overheat and shut down automatically to prevent hardware damage.
D. Configuration Errors and Human Fallibility:
Perhaps the most common cause of outages is simple human error.
-
A Mistyped Command: A single erroneous command by an engineer, such as accidentally deleting a production database or misconfiguring a firewall, can take down an entire service.
-
Inadequate Access Controls: Granting too many permissions to junior staff or failing to implement role-based access control increases the risk of a catastrophic mistake.
E. Targeted Cyberattacks and DDoS Assaults:
Malicious actors continuously target cloud infrastructure.
-
Distributed Denial-of-Service (DDoS) Attacks: These attacks flood a cloud service with more traffic than it can handle, overwhelming its capacity and making it unavailable to legitimate users.
-
Supply Chain Attacks: Compromising a widely used open-source software library or a third-party vendor tool that is integrated into the cloud platform can create a backdoor for disruption.

C. The Ripple Effect: Quantifying the Business Impact of Downtime
When the cloud stumbles, the economic and reputational shockwaves are felt across the globe. The cost of an outage is far more than just lost revenue.
A. Direct Financial Losses:
For e-commerce platforms, streaming services, and online marketplaces, every minute of downtime translates directly to lost sales and transaction fees. The cost varies by industry but can run into millions of dollars per hour for large enterprises.
B. Massive Productivity Loss:
When core business applications—email, CRM, ERP, collaboration tools—are hosted in the cloud and become unavailable, employee productivity grinds to a halt. Projects are delayed, deadlines are missed, and operational momentum is lost.
C. Irreparable Reputational Damage and Erosion of Trust:
Customers experiencing errors and downtime quickly lose confidence in a brand. They may turn to competitors, and negative sentiment can spread rapidly on social media, causing long-term damage to a company’s reputation that far outweighs the short-term financial loss.
D. Data Corruption and Integrity Issues:
In some outage scenarios, particularly those involving storage systems, data can become corrupted or inconsistent. Recovering from this state can be a complex and time-consuming process, potentially leading to permanent data loss.
E. Compliance and Regulatory Penalties:
For businesses in highly regulated industries like finance (PCI-DSS) and healthcare (HIPAA), prolonged downtime can constitute a breach of compliance obligations, resulting in significant fines and legal repercussions.
D. Building a Fortress: Essential Strategies for Cloud Resilience
While you cannot prevent every cloud outage, you can architect your systems to be resilient and ensure your business can withstand them. Here is a strategic action plan.
A. Architect for High Availability from the Ground Up:
Design your applications with failure in mind.
-
Implement Multi-AZ (Availability Zone) Deployment: Every major cloud provider partitions their regions into multiple, isolated data centers known as Availability Zones (AZs). Deploying your application across at least two AZs ensures that a failure in one zone does not take down your entire system.
-
Adopt a Multi-Region Strategy for Critical Workloads: For mission-critical applications, go a step further by deploying across different geographic regions. This protects you from a catastrophic event that could take down an entire region.
-
Design with Microservices and Redundancy: Break your application into small, independent services (microservices). If one service fails, it doesn’t necessarily bring down the entire application. Ensure every component has redundant backups.
B. Embrace a Proactive Multi-Cloud or Hybrid-Cloud Approach:
While complex, diversifying your cloud providers can be a powerful risk mitigation strategy.
-
Multi-Cloud: Using services from two or more cloud providers (e.g., AWS and Azure) for different workloads or for active-active redundancy. This prevents a single provider’s outage from crippling your entire operation.
-
Hybrid-Cloud: Maintaining a portion of your infrastructure in a private data center or colocation facility while using the public cloud for other functions. This provides a fallback option if the public cloud becomes unavailable.
C. Master the Art of Robust Monitoring and Alerting:
You cannot fix what you cannot see.
-
Implement Comprehensive Monitoring: Use tools like Amazon CloudWatch, Azure Monitor, or Google Cloud Operations Suite to track the health and performance of every component of your system.
-
Set Up Meaningful Alerts: Configure alerts not just for when a service is down, but for early warning signs like rising latency, increased error rates, or declining memory availability. This allows for proactive intervention before a full outage occurs.
-
Conduct Regular Chaos Engineering Drills: Proactively inject failures into your non-production environments (e.g., randomly shutting down instances, simulating network latency) to test your system’s resilience and identify weak points before they cause a real outage.
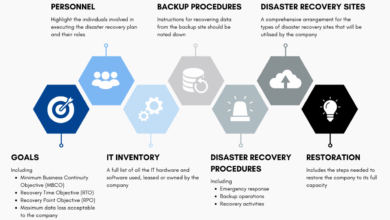
D. Develop and Test a Comprehensive Disaster Recovery (DR) Plan:
Hope is not a strategy. You must have a documented, practiced plan.
-
Define RTO and RPO:
-
Recovery Time Objective (RTO): The maximum acceptable amount of time your application can be offline.
-
Recovery Point Objective (RPO): The maximum amount of data loss you can tolerate, measured in time.
-
-
Automate Your Failover and Backup Processes: Manual recovery processes are slow and error-prone. Automate the process of failing over to a backup region and restoring from backups. Regularly test these automated procedures to ensure they work as expected.
-
Establish Clear Communication Protocols: During an outage, communication is critical. Define exactly how you will communicate with customers, stakeholders, and internal teams to provide transparent and timely updates.
E. Navigating an Active Outage: A Crisis Management Checklist
When an outage occurs, panic is the enemy. A calm, methodical response is essential.
A. Step 1: Confirm and Declare: Verify the issue is widespread and not just a local problem. Officially declare an incident to mobilize your response team.
B. Step 2: Assemble the Response Team: Gather key personnel from engineering, operations, communications, and customer support.
C. Step 3: Communicate Transparently: Use status pages, social media, and email to acknowledge the issue. Be honest about what you know and don’t know. Provide regular updates, even if there is no progress.
D. Step 4: Execute the DR Plan: If the outage is severe and prolonged, initiate your documented disaster recovery procedures to fail over to your backup infrastructure.
E. Step 5: Focus on Restoration, Not Root Cause: The immediate priority is to restore service. The forensic analysis to determine the root cause can happen after service is stable.
F. Step 6: Conduct a Thorough Post-Mortem: Once the crisis is over, conduct a blameless post-mortem to analyze what happened, what was done well, and what needs to be improved. Update your systems and processes accordingly.
Conclusion: Embracing Resilience in an Imperfect Cloud
The recent major cloud outage serves as a stark and valuable lesson: the cloud is a marvel of modern engineering, but it is not infallible. It is a complex system managed by humans and built on physical infrastructure, both of which are susceptible to error and failure. The goal for modern businesses is not to achieve a mythical state of 100% uptime, but to build systems and processes that are resilient enough to withstand inevitable failures with minimal impact. By understanding the root causes, architecting for failure, implementing a robust multi-layered strategy, and practicing diligent crisis management, organizations can transform their relationship with the cloud. They can move from being vulnerable passengers to becoming confident pilots, navigating the occasional turbulence and emerging stronger, more reliable, and more trusted by their customers. The future of cloud computing belongs to the resilient.